

처음엔 1963년 미국표준협회에서 알파벳 뿐만 아니라 0,1~9 까지 숫자와 ! @ # $ 등의 특수문자들을 7비트의 기계어로 표현하는 표준안을 제안한 코드이름이 아스키코드 American Standard Code for information interchange)를 사용하였는데,
이 아스키 코드는 7비트로서 컴퓨터나 인터넷상에서 텍스트 파일을 위한 가장 일반적인 형식입니다.
ASCII 파일에는 각각의 알파벳이나 숫자 그리고 특수 문자들이 7비트 (0000000~1111111)이며 그외에 주소가 넘어가면 윈도우NT 계열의 기본값인 유니코드를 쓰게됩니다.
이것은 아스키코드의 코드표입니다.
|
10진수 |
ASCII |
10진수 |
ASCII |
10진수 |
ASCII |
10진수 |
ASCII |
|
0 |
NULL |
32 |
SP |
64 |
@ |
96 |
. |
|
1 |
SOH |
33 |
! |
65 |
A |
97 |
a |
|
2 |
STX |
34 |
" |
66 |
B |
98 |
b |
|
3 |
ETX |
35 |
# |
67 |
C |
99 |
c |
|
4 |
EOT |
36 |
$ |
68 |
D |
100 |
d |
|
5 |
ENQ |
37 |
% |
69 |
E |
101 |
e |
|
6 |
ACK |
38 |
& |
70 |
F |
102 |
f |
|
7 |
BEL |
39 |
` |
71 |
G |
103 |
g |
|
8 |
BS |
40 |
( |
72 |
H |
104 |
h |
|
9 |
HT |
41 |
) |
73 |
I |
105 |
i |
|
10 |
LF |
42 |
* |
74 |
J |
106 |
j |
|
11 |
VT |
43 |
+ |
75 |
K |
107 |
k |
|
12 |
FF |
44 |
` |
76 |
L |
108 |
l |
|
13 |
CR |
45 |
- |
77 |
M |
109 |
m |
|
14 |
SO |
46 |
. |
78 |
N |
110 |
n |
|
15 |
SI |
47 |
/ |
79 |
O |
111 |
o |
|
16 |
DLE |
48 |
0 |
80 |
P |
112 |
p |
|
17 |
DC1 |
49 |
1 |
81 |
Q |
113 |
q |
|
18 |
SC2 |
50 |
2 |
82 |
R |
114 |
r |
|
19 |
SC3 |
51 |
3 |
83 |
S |
115 |
s |
|
20 |
SC4 |
52 |
4 |
84 |
T |
116 |
t |
|
21 |
NAK |
53 |
5 |
85 |
U |
117 |
u |
|
22 |
SYN |
54 |
6 |
86 |
V |
118 |
v |
|
23 |
ETB |
55 |
7 |
87 |
W |
119 |
w |
|
24 |
CAN |
56 |
8 |
88 |
X |
120 |
x |
|
25 |
EM |
57 |
9 |
89 |
Y |
121 |
y |
|
26 |
SUB |
58 |
: |
90 |
Z |
122 |
z |
|
27 |
ESC |
59 |
; |
91 |
[ |
123 |
{ |
|
28 |
FS |
60 |
< |
92 |
\ |
124 |
| |
|
29 |
GS |
61 |
= |
93 |
] |
125 |
} |
|
30 |
RS |
62 |
> |
94 |
^ |
126 |
~ |
|
31 |
US |
63 |
? |
95 |
_ |
127 |
DEL |
"예를 들어 ALT키를 누르시고 64라고 써보시면 "@"가 써질것입니다."
이런식으로 처음엔 아스키코드가 일반화 되었지만, 컴퓨터도 글로벌 화가 되어 다른 언어도 수용할 공간이 없어 마이크로 소프트에선 유니코드라는 코드를 만들어 (정확히는 아스키 코드를 확장) 세계 모든 언어를 수용하게끔 되었습니다.
기본 아스키코드의 메모리 범위인 7비트(0000000~1111111) 에서 유니코드는 16비트 (0000000000000000~1111111111111111) 의 주소로 늘려 다른 언어도 수용할 만한 공간을 마련하였습니다.
하지만 기본 베이스는 아스키코드를 바탕으로 하기 때문에, 영어 부분에선 아스키 코드로 하여도 별 지장이 없습니다.
(하지만 중국 같이 많은 문자가 있는 나라는 유니코드 메모리 구간을 더 늘려달라고 하는 뒷담이..)
====================================================================================
Unicode는 세계 각국의 언어를 통일된 방법으로 표현할 수 있게 제안된 국제적인 코드 규약의 이름이다.
8비트 문자코드인 아스키(ASCII) 코드를 16비트로 확장하여 전 세계의 모든 문자를 표현하는 표준코드이다.
8비트로 표현할 수 있는 256자는 영어나 라틴권 등에서는 문제가 없으나, 한국, 일본, 중국, 아랍 등의 다양한 문자들을 표현하는 데는 한계가 있다. 또한 각 나라마다 같은 코드 값에 다른 글자를 쓰는 방식으로는 국제간의 원활한 자료 교환이 불가능하기 때문에 코드를 16비트 체제로 확장해서 65,536자의 영역 안에 전 세계의 모든 글자를 표시하는 표준안이다.
영어를 사용하는 국가에서는 아스키 코드보다 두 배의 공간이 필요하기 때문에 일반적인 통신 등에서는 그만큼의 낭비가 되지만 유니코드를 이용하면 프로그램을 하나만 만들면 모든 나라들의 글자를 처리할 수 있기 때문에 그만큼 큰 이점도 되는 것이다.
11,172자의 한글을 연속된 공간에 가나다라 순서로 '가'에서 'ㅎ'까지를 코드화하는 방식이 유니코드 기술 위원회(UTC)에서 채택한 유니코드 2.0 규격이다.
Source : http://kmh.ync.ac.kr/encycl/terms/termsU/unicode.htm
이 부분은 제 언어 실력이 없기에 간단하게 정리된 글을 퍼옵니다.
=======================================================================================
윗부분은 아스키 코드에 불과하니, 그 외의 주소 부분인 유니코드는
시작-실행 에서 "CHARMAP"를 쳐보셔서 메모리 값을 찾아보시기 바랍니다.
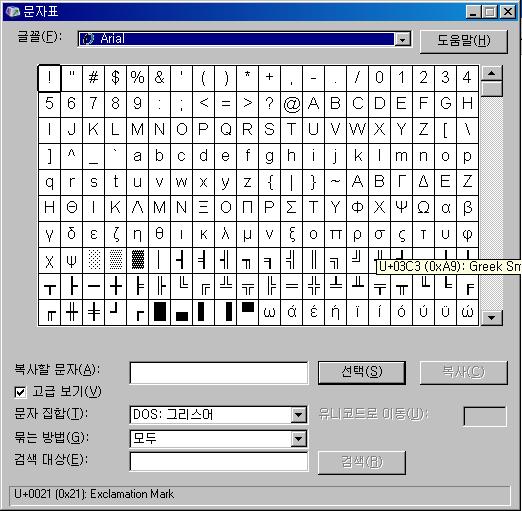
여기서 밑 부분 "U+0021 (0x21): Exclamation Mark
가 보이시나요?
이부분에 U+뒤에 붙은 숫자가 바로 유니코드 주소값입니다. 저기 보이다 시피 "!"가 선택되어있지요?
밑에 보시면 메모리값이 0x21 입니다.
근데 여기서 잠깐! 햇갈리실 부분이 있는데 여기서 ALT키를 누르시고 바로 21 누르신다고 되는것이 아닙니다.
유니코드의 주소값은 16진수라는 것으로 되어있기 때문에, 2x16=32+ 1x1 = 십진수로는 33이 됩니다.
그럼 alt키를 누르시고 33 이라고 입력하시면
!
보시다시피 !표가 입력됩니다.
궁금증이 해결되셨나요??
자세한 유니코드목록을 알고 싶으시면 검색하실때
유니코드표 라고 검색해보시면 됩니다.
여기서 중요한걸 알려드리지 않았군요.;
운영체제의 언어 버전마다 설치되어있는 언어파일이 각각 다르기 때문에, 특정 언어같은 경우 같은 값을 입력하더라도 다른 값을 출력할 수 있습니다. 대표적으로 " ? " 가 있습니다. 이는 운영체제에서 값을 제대로 읽지 못하여 ?로 표시되어나오는것입니다. 이것들을 제대로 표시하기 위해선 언어파일을 반드시 설치해주셔야 하며,
사용하는 OS의 문자열 값이 사용하시려는 메모리값의 언어와 같은 언어로 기본값으로 되어있어야 합니다.
특히 중국어 처럼 언어가 많은 나라의 경우 메모리를 대부분 풀로 씁니다.





